SkySense-VITA: Towards Universal In-context Segmentation of Multi-modal Remote Sensing Imagery
Abstract
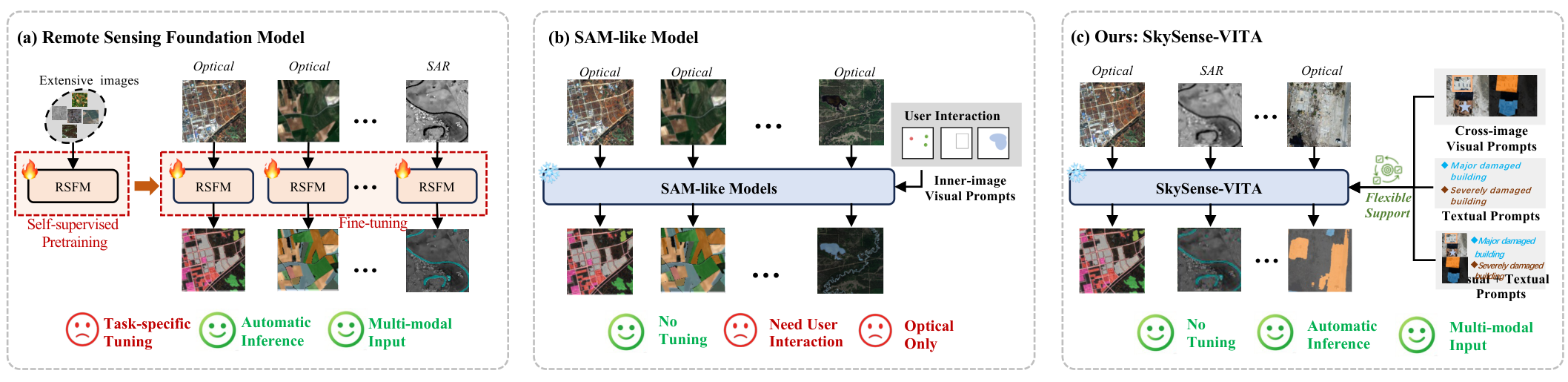
While recent foundation models for remote sensing segmentation have shown notable progress, they still fall short in processing diverse multi-modal inputs, synergizing complementary prompt types, and leveraging semantic hierarchies. To address these limitations, we introduce SkySense-VITA, a unified in-context segmentation model, which synergistically processes both optical and Synthetic Aperture Radar (SAR) imagery using VIsual, TextuAl, or fused prompts. Based on a novel prompt-and-prediction decoupling strategy, we propose the VITA-Former and VITA-Decoder to decouple multi-modal prompt fusion and prediction process, allowing the model to flexibly support visual-only, textual-only, and fused prompt modes. We train SkySense-VITA with a progressive two-stage strategy: a first stage of Image-Level Alignment Pretraining featuring optical-SAR alignment, and a second stage of Pixel-Level In-context Pretraining using Semantic Granularity Annealing (SGA), a coarse-to-fine curriculum that enables robust hierarchical learning. To support this training, we introduce our new large-scale, multi-modal Sky-VT-300k dataset. Extensive experiments show SkySense-VITA establishes a new state-of-the-art on 18 datasets, with an average performance lead of over 10% mIoU.
Method Overview
SkySense-VITA employs a prompt-and-prediction decoupling strategy with two key modules: (1) VITA-Former fuses multi-modal prompt information through learnable modality prototypes and cross-attention, and (2) VITA-Decoder decouples the prediction process with mode-specific queries and block-diagonal masked self-attention, enabling flexible support for visual-only, textual-only, and fused prompt modes.
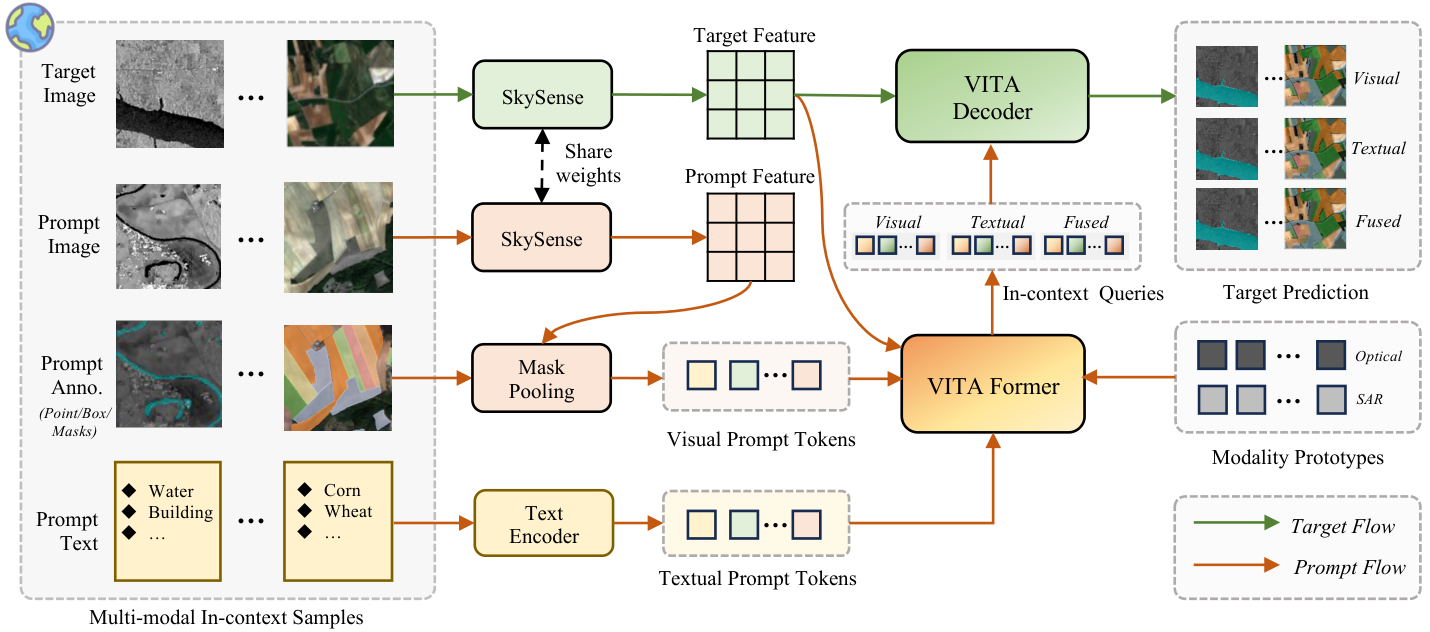
Overall architecture of SkySense-VITA with the VITA-Former and VITA-Decoder modules.
Key Components
VITA-Former
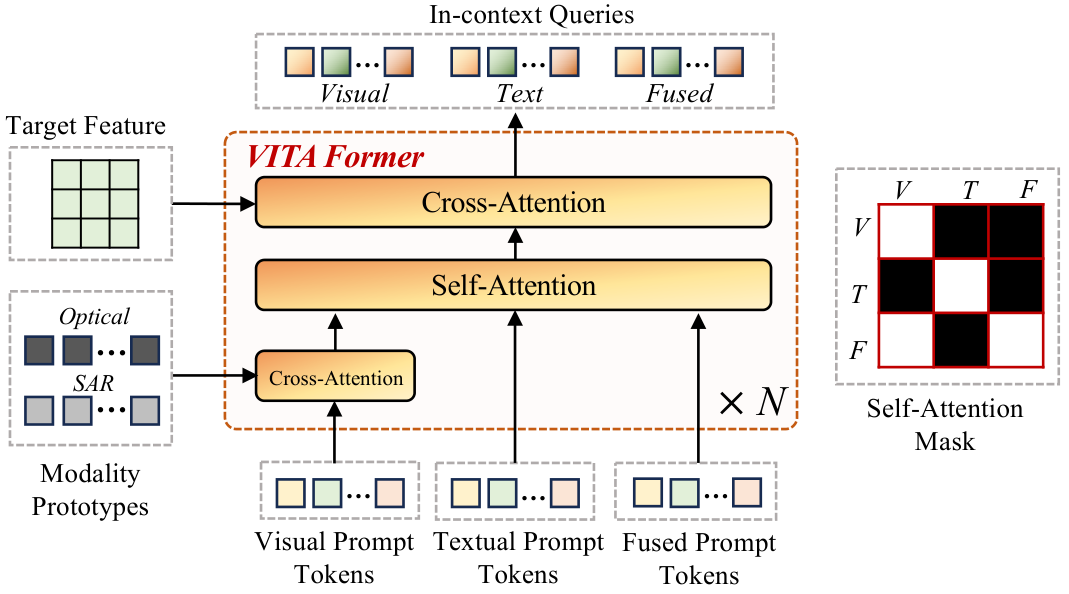
Multi-modal prompt fusion module that integrates visual and textual prompt features through learnable modality prototypes and cross-attention mechanisms.
VITA-Decoder
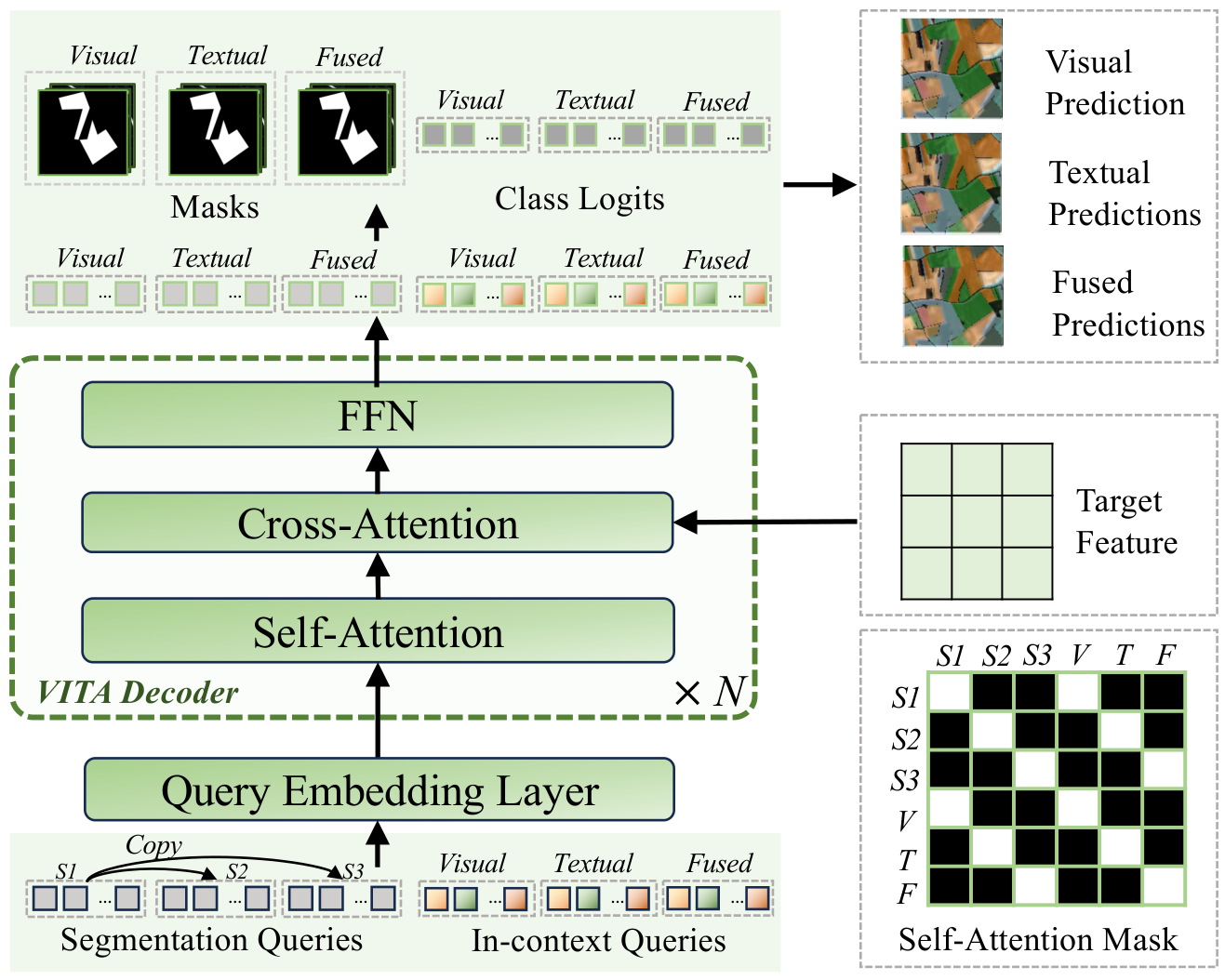
Prompt-guided decoupled decoding module with mode-specific queries and block-diagonal masked self-attention for flexible prompt mode support.
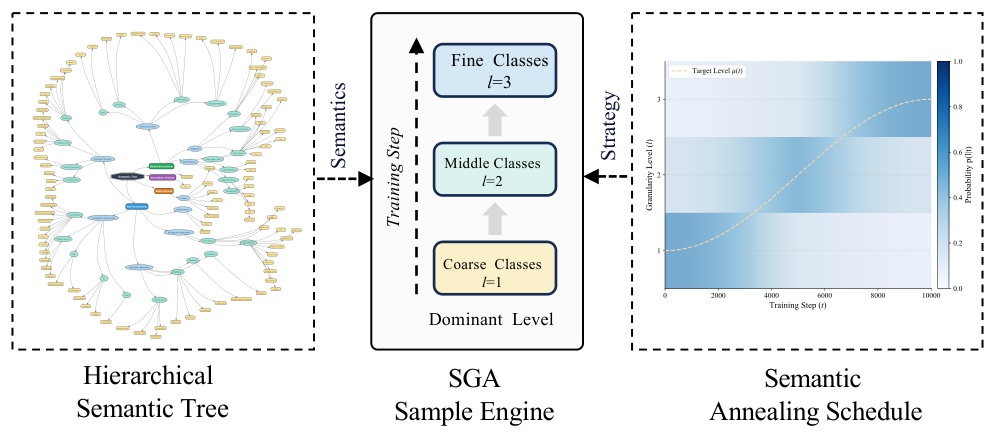
Semantic Granularity Annealing (SGA)
We propose SGA, a coarse-to-fine curriculum learning strategy that progressively anneals the semantic granularity during training. Starting from coarse-grained categories and gradually refining to fine-grained ones, SGA enables robust hierarchical learning across 176 categories in our Sky-VT-300k dataset.
Key Results
18
Datasets Evaluated
SOTA on all benchmarks
>10%
mIoU Improvement
Average lead over prior SOTA
300k+
Training Samples
Sky-VT-300k, 176 categories
Quantitative Comparison
In-Distribution Performance (mIoU %)
Domain Generalization
Class Generalization
Comparison with SAM Series (mIoU %)
Qualitative Results

Qualitative results across diverse remote sensing datasets and prompt modes.
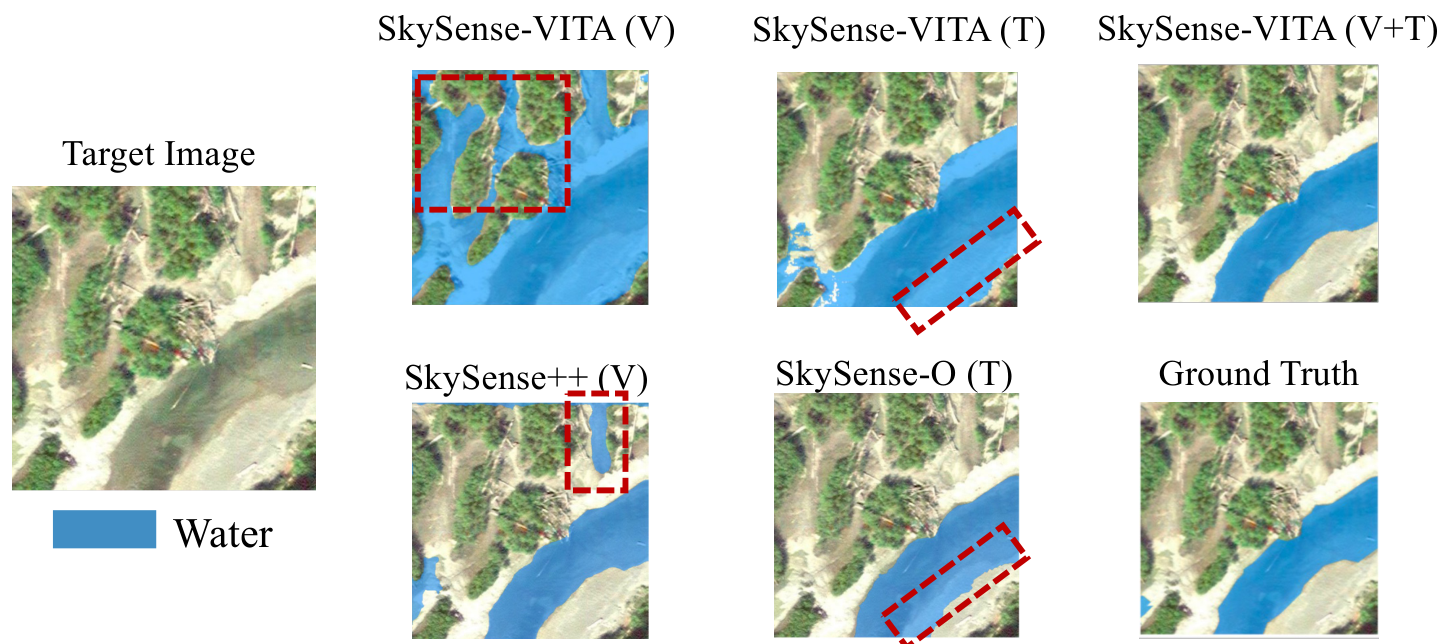
Out-of-distribution generalization results demonstrating robust domain and class transfer.

Qualitative comparison with SAM and SAM2 on multi-modal remote sensing segmentation tasks.
BibTeX
@InProceedings{Wu_2026_CVPR,
author = {Wu, Kang and Yu, Lei and Luo, Junwei and Dang, Bo and Zhang, Junjian and Cai, Xiangyuan and Hu, Hongwei and Chen, Jingdong and Li, Yansheng},
title = {SkySense-VITA: Towards Universal In-context Segmentation of Multi-modal Remote Sensing Imagery},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
pages = {20553-20563}
}